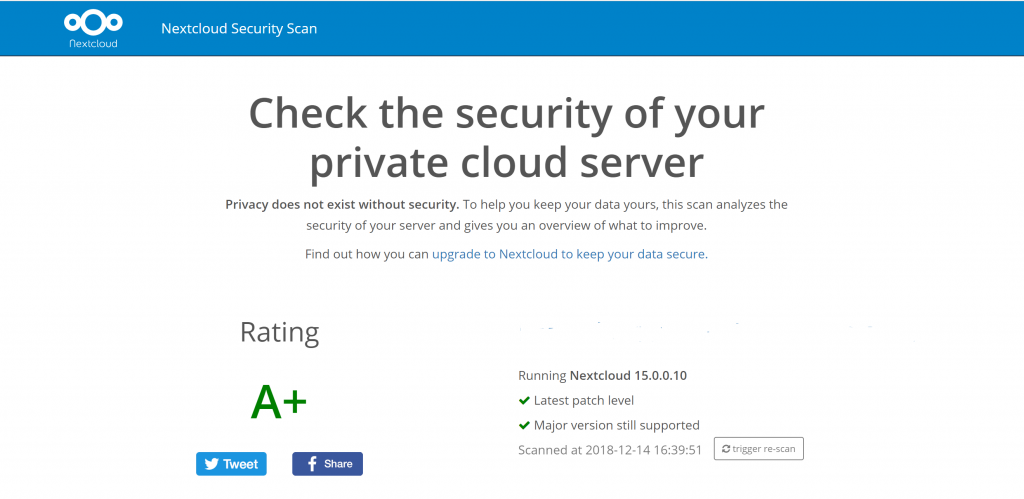
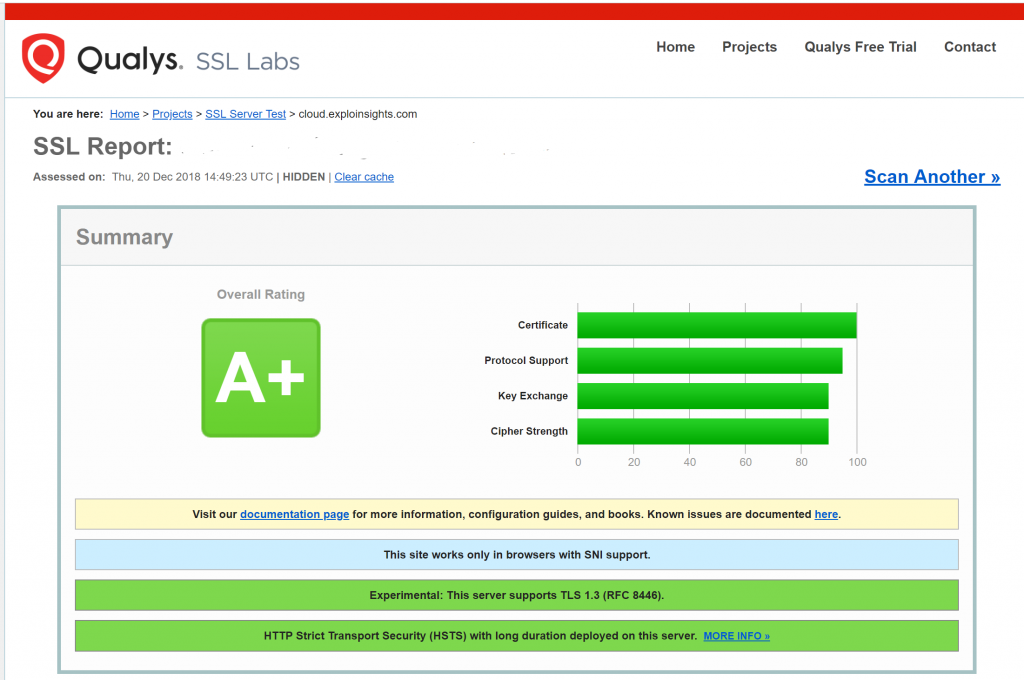
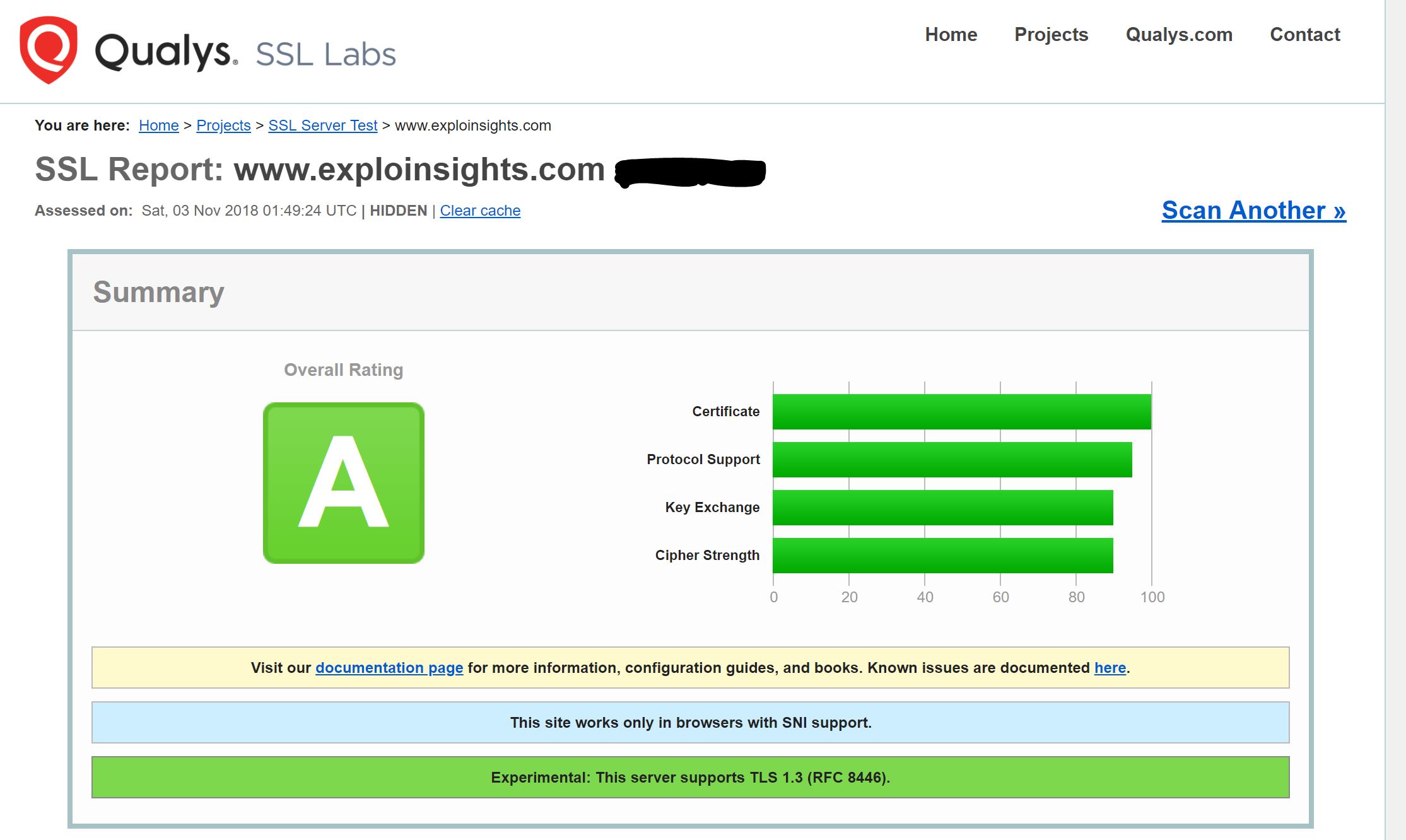
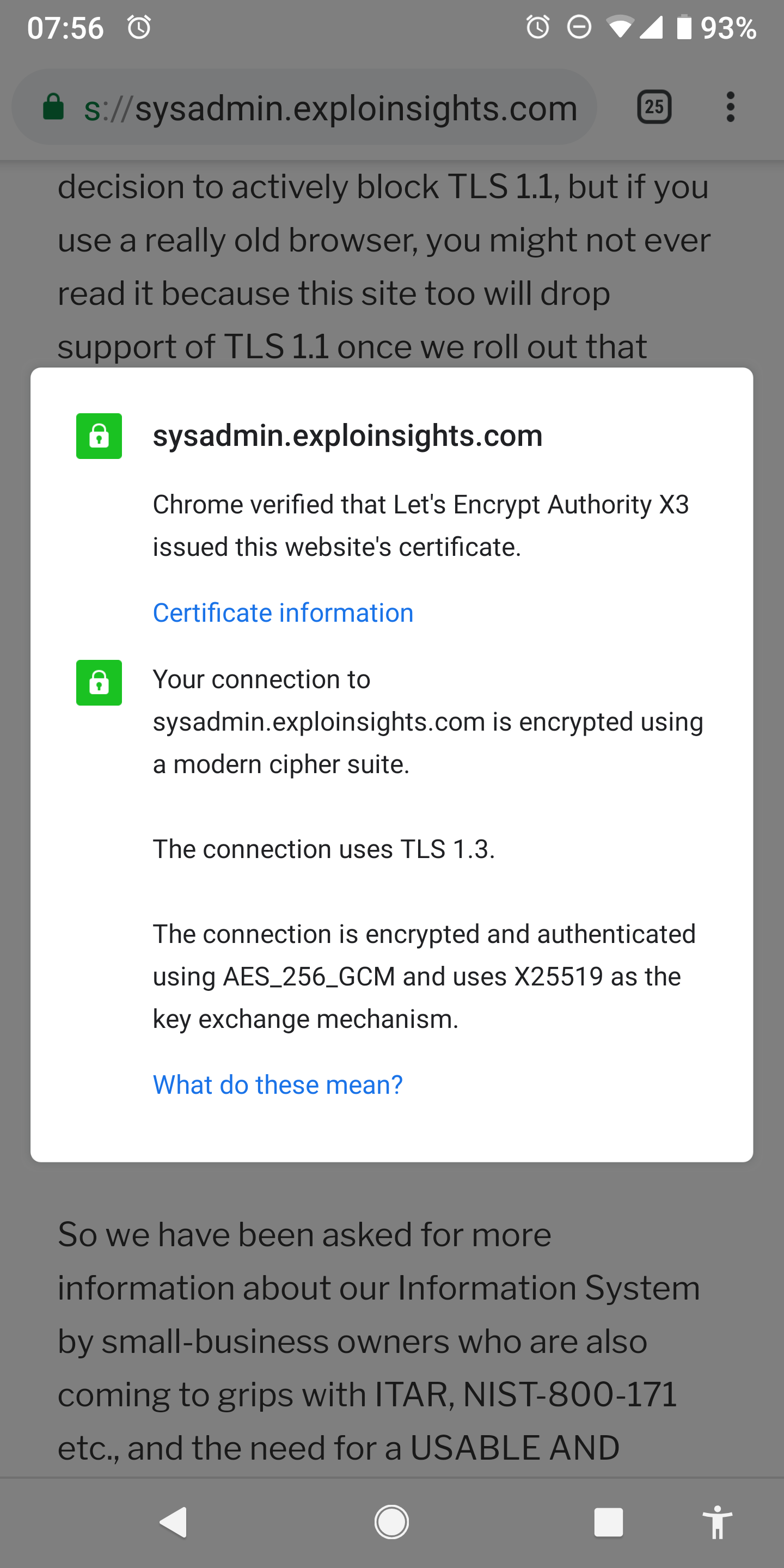
You know I am a fan of Nextcloud. I got so used to having this for my consulting company that even though the company itself is no long with us, the Nextcloud servers found personal utility. that shouldn’t be a surprise for anyone who has looked into Nextcloud.
The big problem for personal users (and even some small businesses) is…the backup strategy for Nextcloud.
You can certainly backup your user data files easily enough – just take a snapshot copy of user files and copy it to e.g. a USB drive and pop it in your safe and you are done. Update it weekly or whatever, and you have a reasonable backup set for your user files. Not terriible, not perfect, but it’s fine. And certainly better than nothing.
But for Nextcloud, a users data files is just one small part of the server. There’s apps, settings, configurations; and shares and links with passwords and expiration dates, and all kinds of ‘nice’ features that, well, also ideally need to be backed up.
If you read online documets, they tell you to run a seperate mysql server via some complicated setup that’s really just not practical for home users. So it seems we’re doomed to just having our files backed up, and if the server goes pooft, we have to rebuild it from ground up – and then go back and add all the finishing touches: apps, user settings, Nextclould configuration options, links, theming etc. etc.
I have previously reported how if you run your Nextcloud server as an lxc container (really simple under Ubuntu linux) then you can copy the containers from one machine to another, and it helps with some of the configurations. But at the time of writing, you had to copy an entire server – that can quickly grow into TB+ storage drives for user data. That’s a slow copy even over a lan (and forget it for wan). And it becomes impracticable for routine (e.g. daily) backups of a server
BUT Now…we have LXD 4.0. And it has a new command option that fixes all of that:
~$: lxc copy container remote:container –refresh
the key word, or rather an option, is –refresh. If you setup a Nextcloud container called (e.g.) nextcloud on a local machine, and you have another, remote machine called (e.g.) BackupServer (can be on same lan or even halfway around the world) then this command copies your container to the other machine without having to stop the existing machine. It copies everything about your instance – it is an exact copy:
~$: lxc copy nextcloud BackupServer:nextcloud –refresh
All you need is two machies running LXD version 4.0 or later and enough HD space for your backup copy (copies). So far so good – the same as prior releases of lxd.
And if you re-run that command say every day you get your offsite copy refreshed to be an updated version of your server – and it only sync’s changes, not the whole server. So your first copy might be slow, but subsequent ones will be quite fast. And there’s no need to stop your local container to copy it (the remote copy however has to be stopped).
You can cron this, so that it makes refreshed copies say daily (or more), and then makes weekly unrefreshed backups after say 7 days, then monthly and so forth. You can have BACKUP copies of OLD servers if you want or need to go back, and you can always have your live version backup daily (or more). Note that multiple backup copies of a server image take up the same space per copy, so storage cost may become an option (but spinning-rust HD’s are cheap, so probably not amajor issue for the home enthusiast or even small business).
If your current server goes down, all you do is start the remote one, point a router to it, maybe update a DNS server (if it’s on a different public IP address) and you are back in business. Same name, links, shares, setttngs, users, data, files, confiuration, settings etc. It all just *works* – just as it should.
You can be up and running in less than five minutes from when you detect your primary server is down. That makes for pretty good uptime availability of your server.
We think this –refresh option is a game-changer for lxd.
Happy Backups!