

Well what a time we had this week. There we were, minding our own business, running a few standard:
sudo apt update && sudo apt upgrade
…commands as our server notified us of routine (so we thought) Ubuntu updates. We have done this many many times. So, what could go wrong?
After this particular update, which included a kernel change, we were given that lovely notice that says “a reboot is required to make changes take effect”. We never like that.
We were out of the office. But this was a security update, so it’s kinda important. #AGONISE-A-LITTLE. So, we went to a backup server first, and performed the same update (it was the same OS and it needed the same patches). We remotely rebooted the backup server and it worked beautifully. That made us feel better (#FalseSenseOfSecurity). So, on our primary server, we issued:
sudo reboot
…at the terminal, as we had done many many times before. As usual, the SSH connection was terminated without notice. We don’t like that, but that’s the nature of the beast. We waited to login into our Dropbear SSH terminal so we can remotely unlock our encrypted drives. With some relief, it appeared! YAY. We typed in our usual single command and hit the return key:
unlock
We normally get a prompt for our decryption credentials. In fact, we ALWAYS get a prompt for our decryption credentials. #NotToday
Not only did we see something new, it was also, as far as we can google, unique for a Dropbear login:
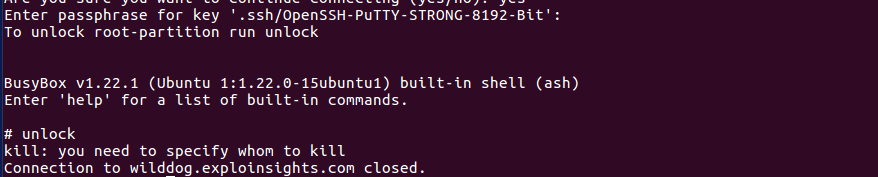
WhiskyTangoFoxtrot (#WTF). We are not trying to kill a process. We are trying to unlock our multiple drives. What is going on? We logged back in, and got the same result. This was not a badly typed command. This was real. Our primary server was down. And we mean DOWN. The Kill process is part of the unlock script, which means the script is not working…which means the OS can’t find the primary encrypted drive. We actually managed to get a remote screen-shot on the terminal, which was even more unnerving (we figured if Dropbear access was broken, maybe we could log in at the console):
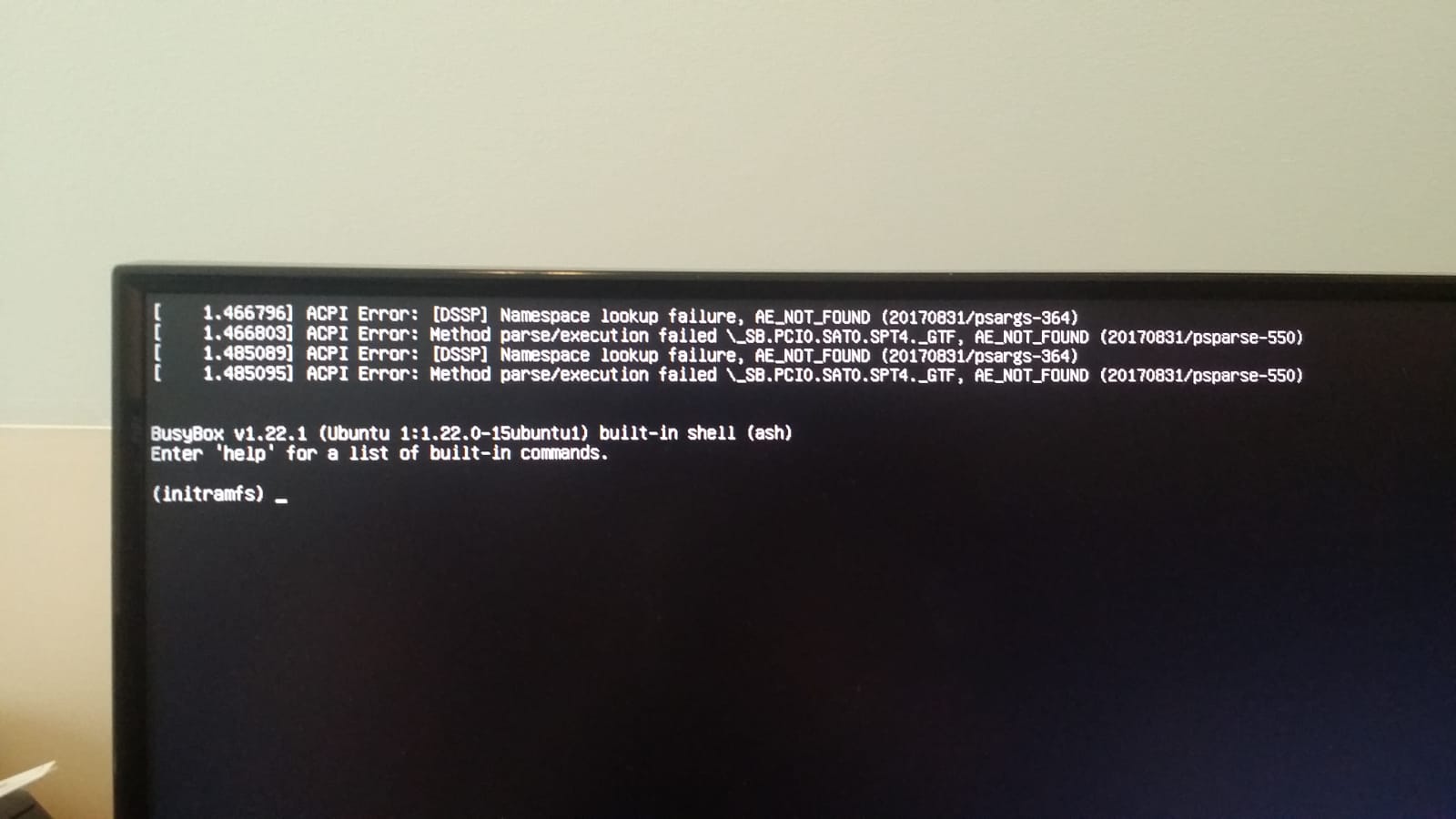
Oh that is an UGLY screen. After about 30 minutes of scrambling (which is too long – #LESSON1), we realised our server was dead until we could physically get back to it. Every office IT service was down: our Nextcloud server (mission-critical), our office document server (essential for on-the-road work), our two web sites (this being one of them). NOTHING worked. Everything is dead and gone. Including of course this web site and all the prior posts.
This was our first real-world catastrophic failure. We had trained for this a couple of times, but did not expect to put that practice into effect.
Today was REAL for us. So, after too long scrambling in vain to fix the primary server (30 minutes of blackout for us and our customers), we 2FA SSH’d into our live backup server (#1 of 2) and reconfigured a few IP addresses. We had virtually complete BACKUP COPIES of our lxc containers on server#2. We fired them up, and took a sharp intake of breath…
And it WORKED. Just as it SHOULD. But we are so glad it did anyway! LXC ROCKS.
Everything was “back to normal” as far as the world would be concerned. It took maybe 15 minutes (we did not time it…) to get everything running again. Web sites, office document file server, cloud server etc. – all up and running. Same web sites, same SSL certs. Same everything. this web site is here (duh), as are all of our prior posts. We lost a few scripts we were working on, and maybe six-months off our lives as we scrambled for a bit.
We don’t yet know what happened to our primary server (and won’t for a few days), BUT we think we hedged bets against ourselves in several ways: we are a small business. So… we use the server hardware for local Desktop work too (it’s a powerful machine, with resources to spare). We now think that’s a weakness: Ubuntu server edition is simply MORE STABLE than Ubuntu Desktop. We knew that, but thought we would get away with it. We were WRONG. Also, we could have lost a little data because our LXC container backup frequency was low (some of these containers are large, so we copy en-mass on a non-daily basis). We think we got lucky. We don’t like that. We think that single LXC backup strategy not ideal now either. We also have all of our backup servers in one geo-location. We have worried about that, and we do a little more so today.
All of these constitute a lessons-learned which we might actually document in a separate future article. But today, boy, do we love our LXC containers.
![]()
But without a shadow of doubt, the primary takeaway here is: if you operate mission critical IT assets, you could do a lot worse than running your services in LXC containers. We know of no downside, only upside. THANK YOU, Canonical.