
So we have seen some postings online that suggested you can’t encrypt an lxd zpool, such as this GitHub posting here, which correctly explains that an encrypted zpool that doesn’t mount at startup disappears WITHOUT WARNING from your lxd configuration.
It’s not the whole picture as it IS possible to so encrypt an lxd zpool with luks (the standard full disk encryption option for Linux Ubuntu) and have it work out-of-the-box at startup, but perhaps it’s not as straightforward as everyone would like
WARNING WARNING – THE INSTRUCTIONS BELOW ARE NOT GUARANTEED. WE USE COMMANDS THAT WILL WIPE A DRIVE SO GREAT CARE IS NEEDED AND WE CANNOT HELP YOU IF YOU LOSE ACCESS TO YOUR DATA. DO NOT TRY THIS ON A PRODUCTION SERVER. SEEK PROFESSIONAL HELP INSTEAD, PLEASE!
With that said…this post is for those who, for example, have a new clean system that they can always do-over if this tutorial does not work as advertised. Ubuntu OS changes and so the instructions might not work on your particular system.
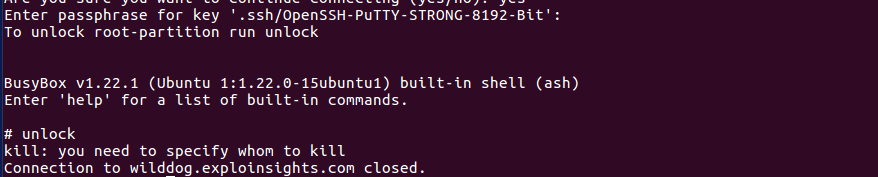
Firstly, we assume you have your ubuntu 16.04 installed on a luks encrypted drive (i.e. the standard ubuntu instal using the “encrypt HD” option). This of course requires you to enter a password at boot-up to decrypt your system, something like:
We assume you have a second drive that you want to use for your linux lxd containers. That’s how we roll our lxd.
So, to setup an encrypted zpool, select your drive to be used (we assume it’s /dev/sdd here, and we assume it’s a newly created partition that is not yet formatted – your drive might be /dev/sda, /dev/sdb or something quite different – MAKE SURE YOU GET THAT RIGHT).
Go through the normal luks procedure to encrypt the drive:
sudo cryptsetup -y -v luksFormat /dev/sdd
Enter the password and NOTE THE WARNING – this WILL destroy the drive contents. #YOUHAVEBEENWARNED
Then open it:
sudo cryptsetup luksOpen /dev/sd?X sd?X_crypt
Normally, you would create your normal file system now, such as an ext4, but we don’t do that. Instead, create your zpool (we are calling ours ‘lxdzpool’ – feel free to change that to ‘tank’ or whatever pool name you prefer):
sudo zpool create -f -o ashift=12 -O normalization=formD -O atime=off -m none -R /mnt -O compression=lz4 lxdzpool /dev/mapper/sdd_crypt
And there you have an encrypted zpool. Add it to lxd using the standard ‘sudo lxd init’ procedure that you need to go through to create lxc containers, then start launching your containers and voila, you are using an encrypted zpool.
So, we are not done yet. We can’t let the OS boot up without decrypting the zpool drive, lest our containers disappear and lxd goes back to using a directory for its zpool, per the GitHub posting referred to above. That would not be good. So how do we make sure this is auto-decrypted at boot-up (which is needed for lxc containers to launch)?
Well, we have to create a keyfile that is used to decrypt this drive after you decrypt the main OS drive (so you do still need to decrypt your PC at bootup as usual – as above):
sudo dd if=/dev/urandom of=/root/.keyfile bs=1024 count=4
sudo chmod 0400 /root/.keyfile
sudo cryptsetup luksAddKey /dev/sdd /root/.keyfile
This creates keyfile at /root/.keyfile. This file is used to decrypt the zpool drive. Just answer the prompts that these commands generate (self explanatory).
Now find out your disks UUID number with:
sudo blkid
This should give you a list of your drives with various information. We need the long string that comes after “UUID=…” for your drive, e.g.:
/dev/sdd: UUID=”971bf7bc-43f2-4ce0-85aa-9c6437240ec5″ TYPE=”crypto_LUKS”
Note we need the UUID – not the PARTUUID or anything else. It must say “UUID=…”.
Now edit /etc/crypttab as root:
sudo nano /etc/crypttab
And add an entry like this:
#Add entry to aut-unlock the encrypted drive at boot-up,
#after the main OS drive has been unlocked
sdd_crypt UUID=971bf7bc-43f2-4ce0-85aa-9c6437240ec5 /root/.keyfile luks,discard
And now reboot. You should see your familiar boot-up screen for decrypting your ubuntu OS. And once you enter the correct password, the encrypted zfs zpool drive will be automatically decrypted and will allow lxd to access it as your zpool. Here’s an excerpt from our ‘lxc info’ output AFTER a reboot. We highlighted the most important bit for this tutorial:
$ lxc info
config:
storage.zfs_pool_name: lxdzpool
api_extensions:
– id_map
– id_map_base
– resource_limits
api_status: stable
api_version: “1.0”
auth: trusted
auth_methods: []
public: false
driver: lxc
driver_version: 2.0.8
kernel: Linux
kernel_architecture: x86_64
kernel_version: 4.15.0-34-generic
server: lxd
storage: zfs
Note we are using our ‘lxdzpool’.
We hope this is useful. GOOD LUCK!
Useful additional reference materials are here (or at least, they were here when we posted this article):
Encrypting a second hard drive on Ubuntu (post-install)
Setting up ZFS on LUKS


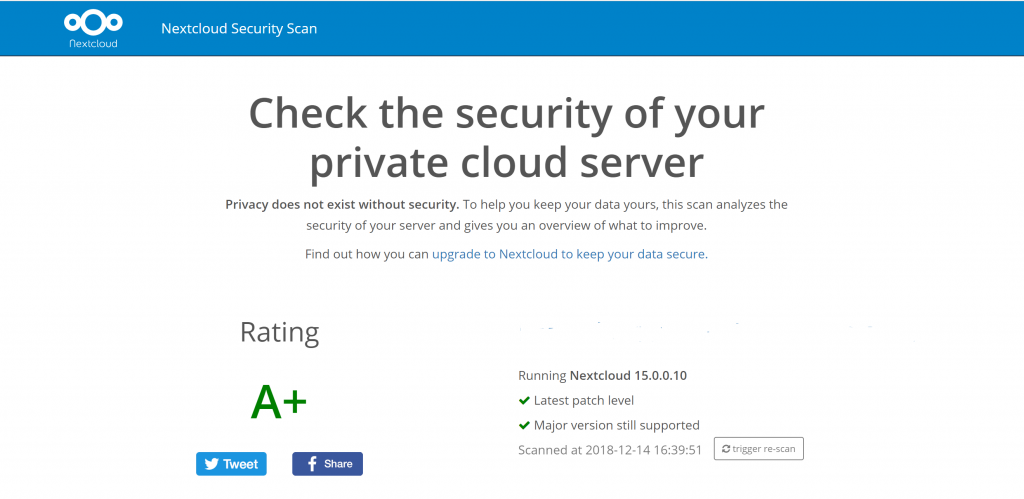
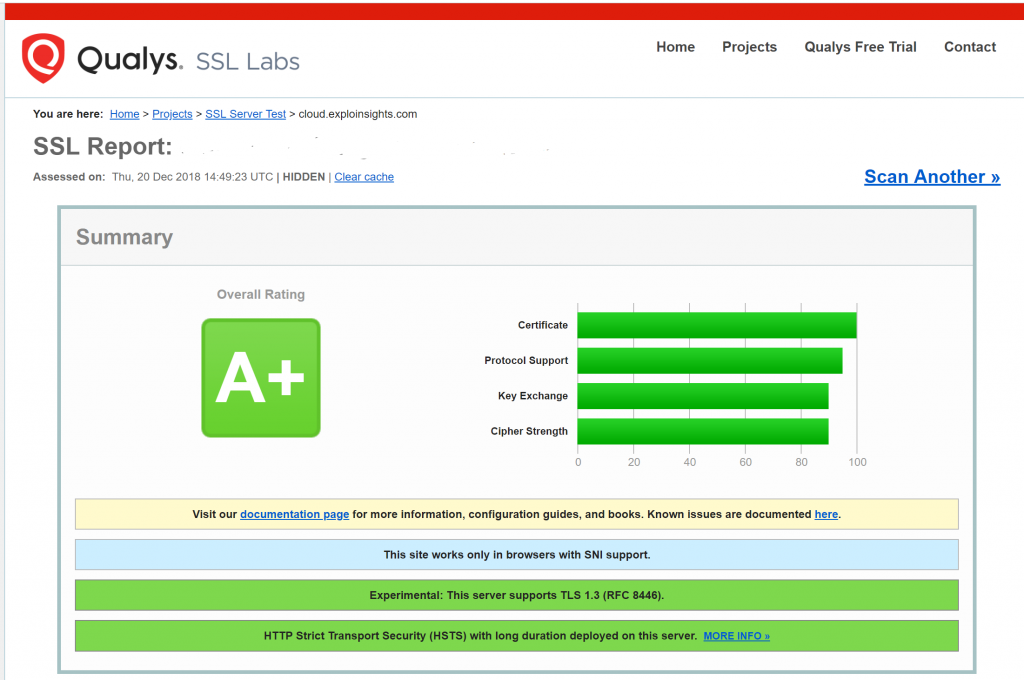

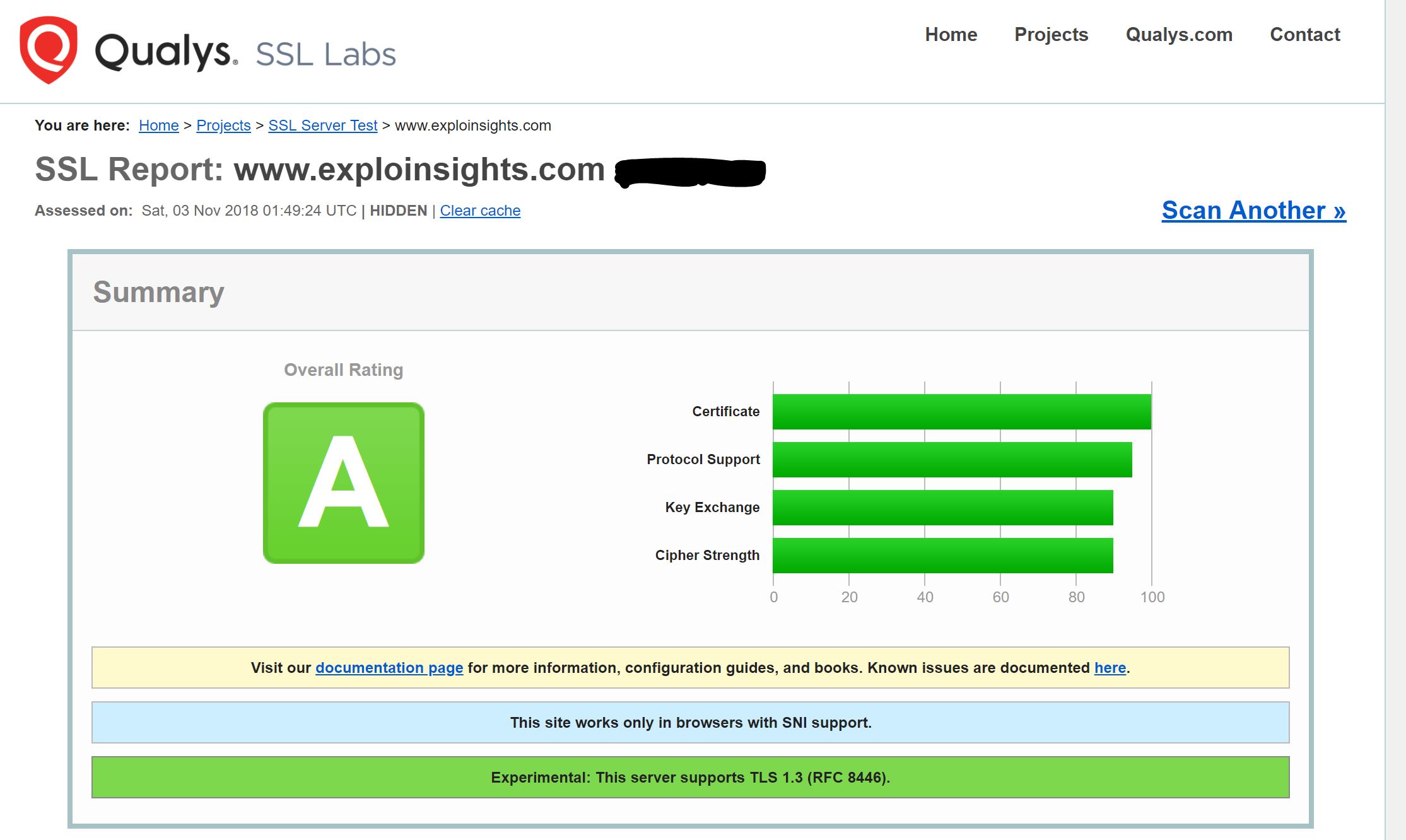
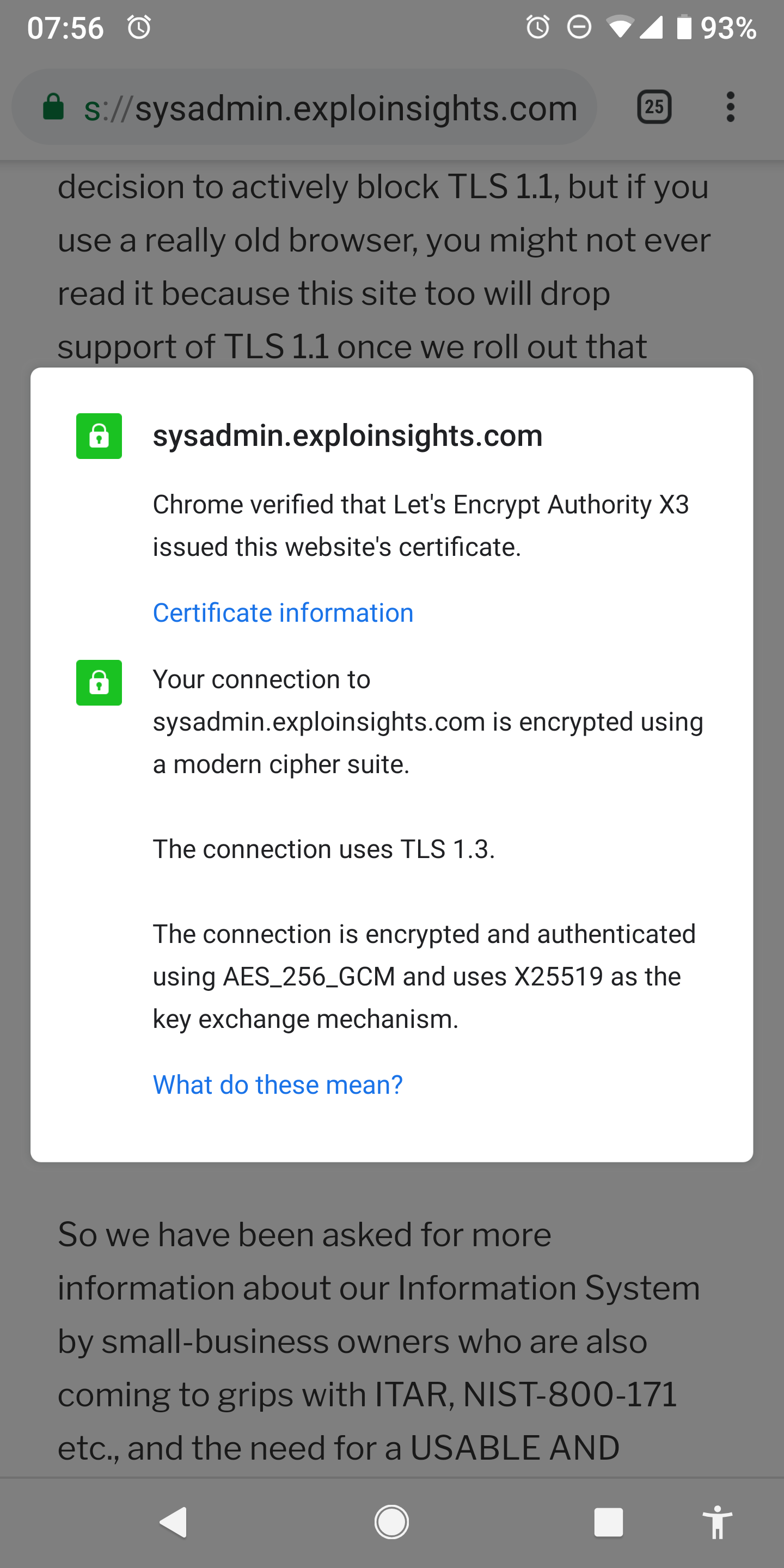


 Our favorite new command-of-the-day:
Our favorite new command-of-the-day: