So like all SysAdmins, we have a lot to worry about in order to continually meet the burdens of compliance. For us, data residency (location) and digital “state” (encryption status) is very important.
We have had a productive few days improving the PERFORMANCE of our systems by using better-integrated software. So, why is PERFORMANCE being addressed under compliance? Well, simply, because if you make a compliant system easier to use, users are more likely to use them, and thus be more compliant.
It’s no secret, we are great fans of Nextcloud – we self-host our cloud server, and because we use that to host our data, we use several different security layers to help thwart accidental and malicious exposure. Our cloud server, based at our office HQ in Tennessee, is where we store all of our important data. So we try to make it secure.
Firstly, our cloud server can only be accessed by HTTPS (SSL/TLS). Logging in requires 2FA credentials:
This gets you to the next step:

So this is good. And we have server-side encryption enabled in Nextcloud, which provides an additional layer of security – not even the SysAdmin can read the client data on the server.
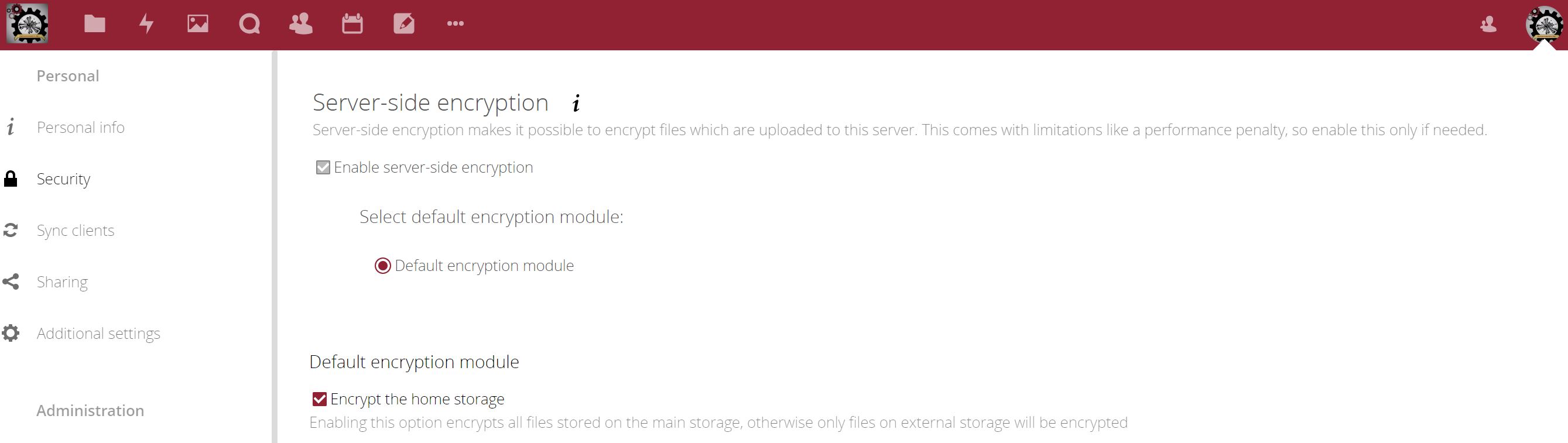
This is cool. Server-side encryption does help us with sharing of files to customers, but because the decryption key is stored on the server, we don’t like to rely solely on that for protecting our important data.
So our data are end-to-end encrypted with Cryptomator – an open source, AES encryption software package, with apps for Linux, Windows and Android (we use all three) – and even apps for IOS for those that like their Apples too (we don’t).

Of course, one of the things that makes this system “inconvenient” is that it’s hard to access end-to-end cloud-encrypted files quickly. On the server, they look like THIS:
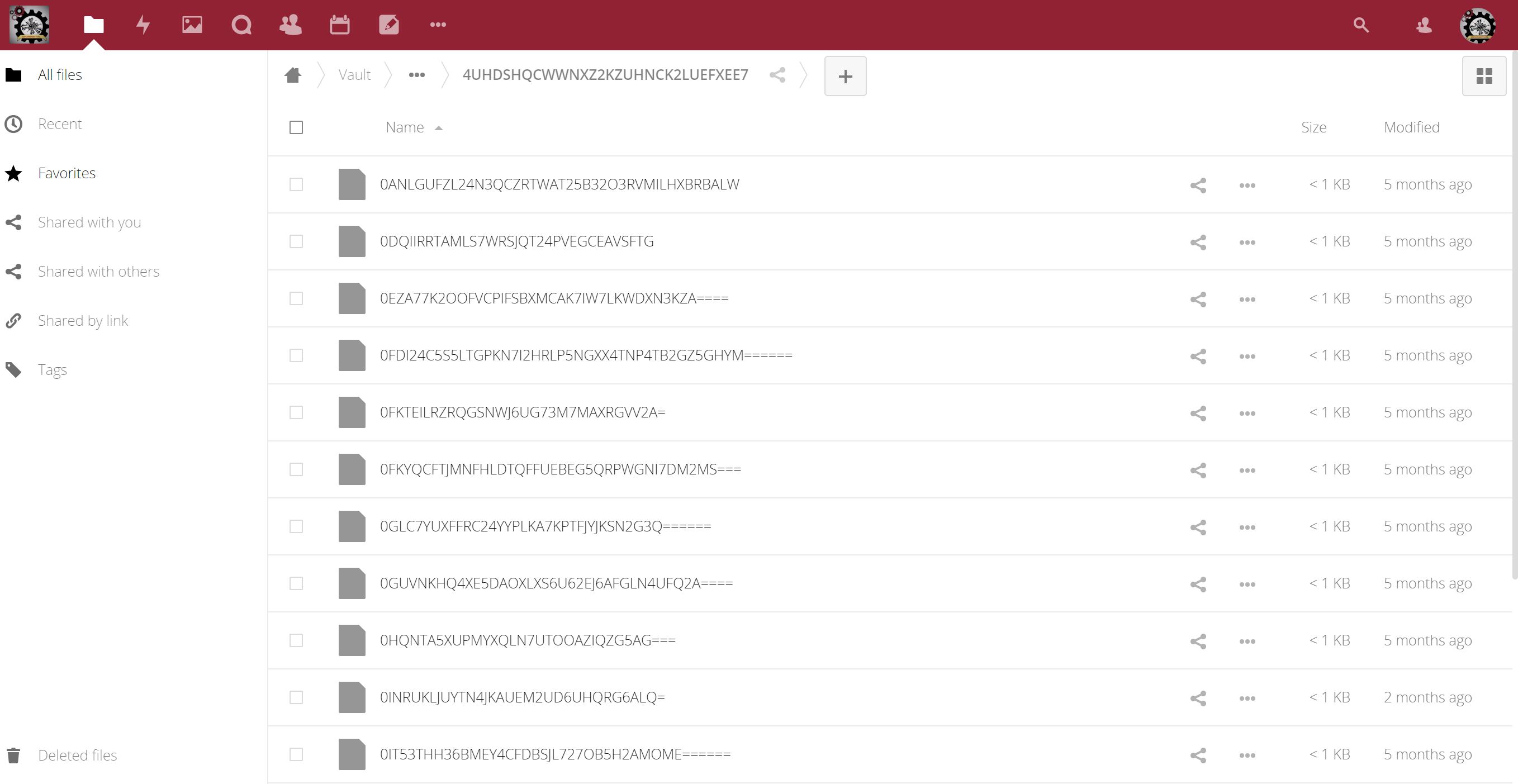
Not entirely useful. Really hard to work on a file like this. You have to physically download your encrypted file(s) (say using the webdav sync software platform, like the great one provided by Nextcloud) and store them locally on your device, then decrypt them locally, on your device, so you can work on them. This is fine when you are in your office, but what about when you are on the road (as we often are)?
Data residency and security issues can arise with this method of working when on travel, so you can’t download files en-mass to your device and decrypt them all when you are in the “wrong place”. You have to wait until you can get back to a right location before you can work. Customers don’t really like the delays this can cause them, and we don’t blame them. And worse still, in that situation, even when you are done, you have to delete (or even ERASE) files on your PC if you are going back on travel etc. again to a location where data residency becomes an issue. Then when you get to a secure location again, you have to repeat this entire process for working on your files again. This is hard to do. Believe us, we know, as we have had to do this, but we now have a better way.
A more secure but LESS CONVENIENT way is to somehow only download the files you need as you need them, and decrypt and work on them etc. ONLY AS YOU NEED THEM. This is more secure, as you only have one decrypted file on your device (the one you are working on in your word processor etc), but how can that be done and be done CONVENIENTLY?
Obviously, this “convenience v security” issue is one we have spent a lot of time looking at. We have used webdavs connected to our cloud servers and tried to selectively sync folder(s). It’s not efficient, not pretty, not fast (actually really slow) and sometimes it just doesn’t work.
But thankfully we now have a much faster, reliable, efficient, effective yet totally compliant way of addressing the problem of keeping files end-to-end encrypted yet still be able to work on them ONE AT A TIME even when you are in a location that can otherwise bring data residency issues.
For us, this requires several systems that have to work together, but they are built (mostly) on Open Source software that has, in some cases, been tried and tested for many years so is probably as good as you can get today:
- OpenSSH – for Secure Shell connectivity;
- Nextcloud server;
- Nextcloud sync clients;
- Cryptomator;
- 2FA Authentication credential management apps;
- And last but not least…Mountain Duck.
SSH is an established, reliable secure service used globally to securely connect to servers. If configured correctly, they are very reliable. We believe ours are configured properly and hardened, not least because NONE of our SSH connections work with a username/password login. Every connection requires a strong public/private key combination, and every key itself is further password protected; and, each SSH connection ALSO requires a second-factor (2FA) code. We think that’s pretty good. We have already explained Nextcloud and Cryptomator. 2FA apps are the apps that generate the six-digit code that changes on your phone every 30 seconds. We have written about a new one we like (PIN protected), so we won’t go into that anymore. That leaves ‘Mountain Duck’. Yes ‘Mountain Duck‘. We know, it’s not a name one naturally gives to a secure file-access system, but bear with us (and in any case, we didn’t name it!). Put simply, Mountain duck allows us to use our 2FA protected SSH connections to our servers to access our files, but it does so in a really neat way:
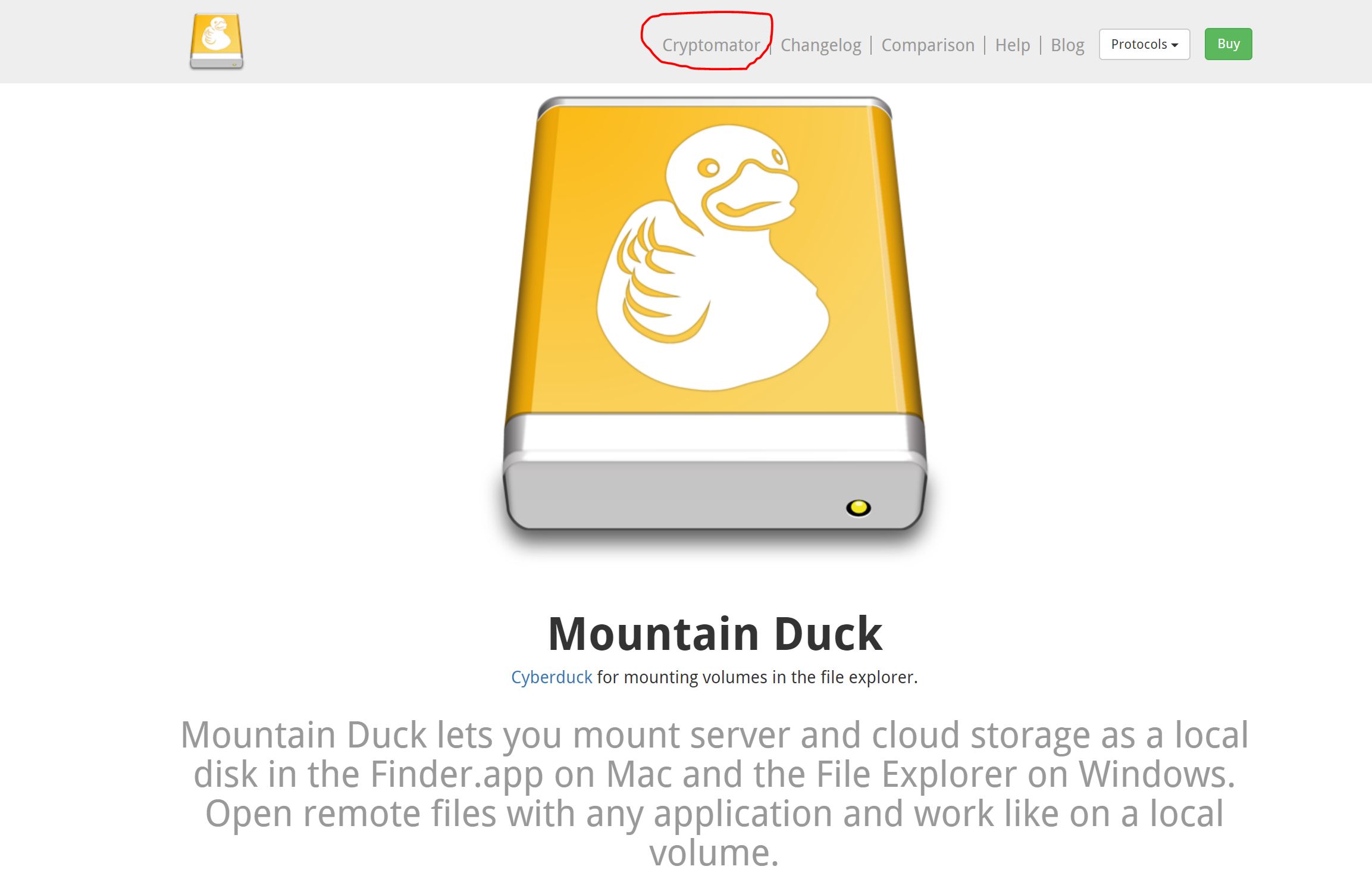
In the image above, taken from their we site, note the text we circled in red. Mountain Duck comes with CRYPTOMATOR integration. So this effectively makes Mountain Duck a ‘Windows explorer’ that can be 2FA-connected via SSH to a server to access and decrypt in real-time Cryptomator end-to-end encrypted files stored on our HQ-based servers. To that, we say:
Just WOW.
So how does this work in the real world; how do we use this?
Well we have a Nextcloud sync client that syncs each users files to a separate LXC container running on the corporate server. Each container is used to sync the users files between the Nextcloud server and the Nextcloud user files. Both the Nextcloud server AND the Nextcloud client files are ultimately stored in the HQ facilities, albeit in very different LXC containers. Files are end-to-end encrypted in both the Nextcloud server and the Nextcloud client container. All are further protected by full disk encryption and SSL/TLS connectivity.
Whether we are on the road OR in the office, we work on our files by logging into our Nextcloud client container using OpenSSH and Mountain Duck.
It’s all a lot simpler than it might sound: First, we connect to our Nextcloud client containers via strong SSH credentials via Mountain Duck’s friendly interface, which asks first for our private key password:
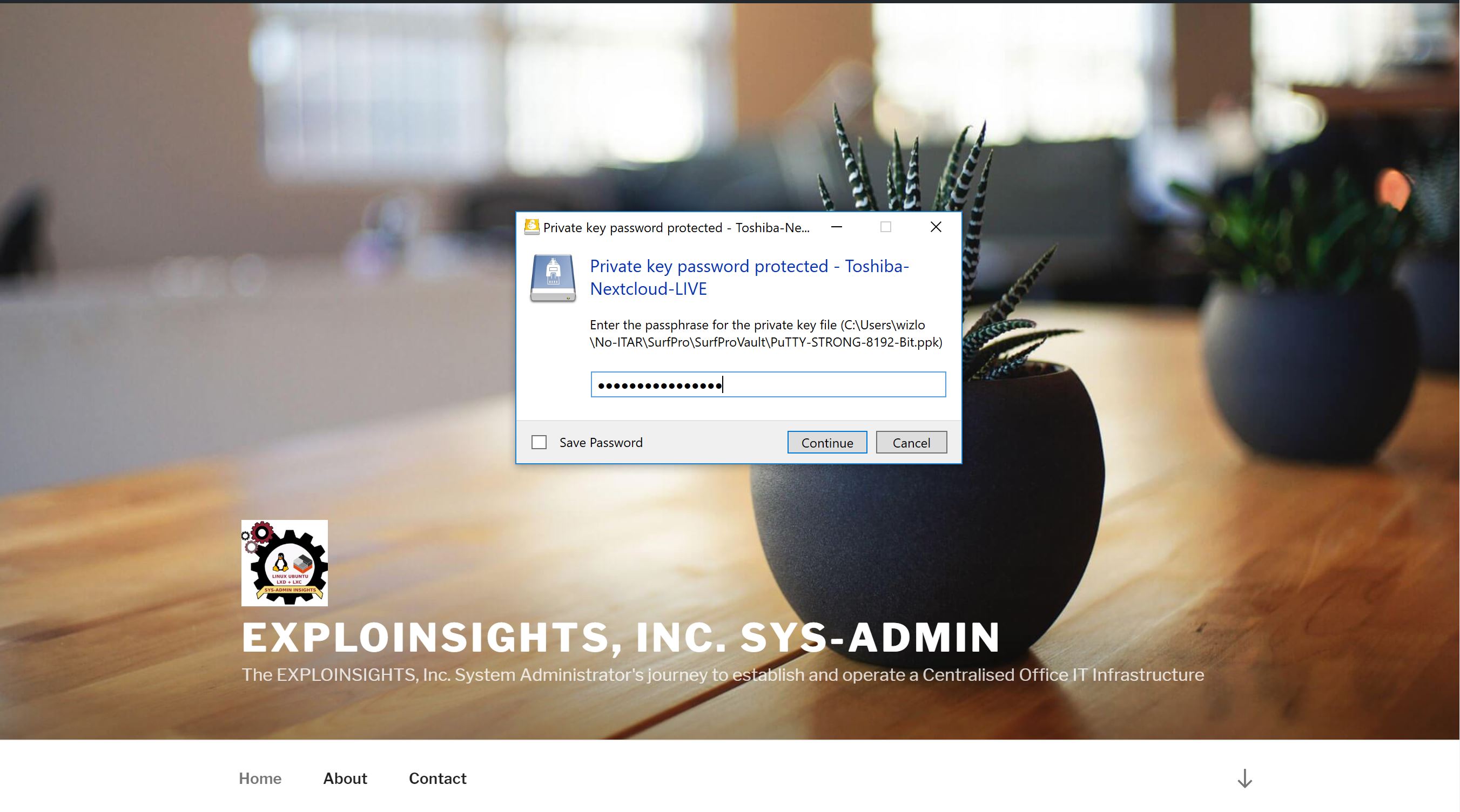
And then asks for our 2FA code:
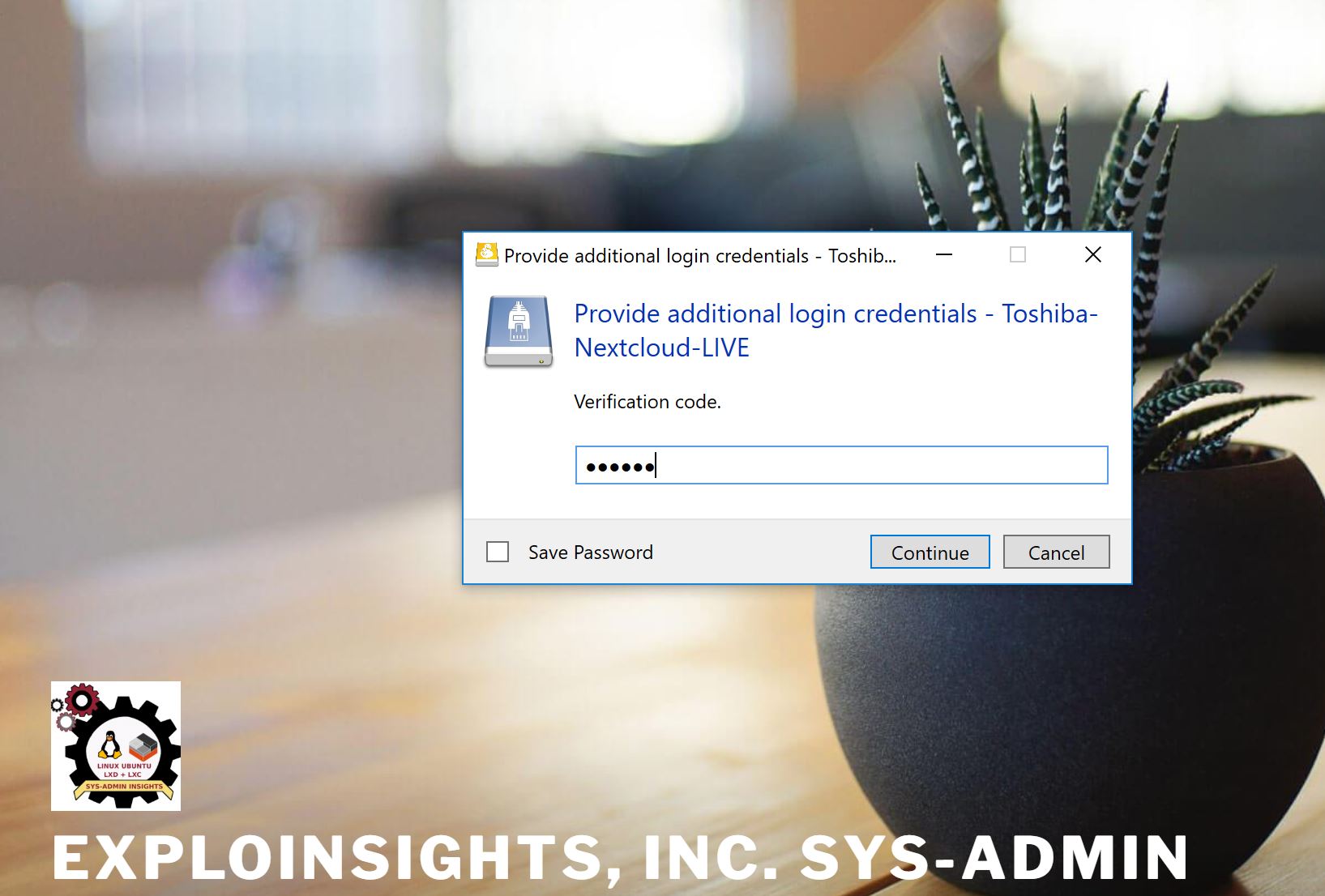
The 2FA code is generated on an our 2FA App on our encrypted, locked android smartphone, in a PIN protected app (We use ‘Protectimus‘ and also ‘andOTP‘).
With these credentials, Mountain Duck logs into our Nextcloud client container via the secure SSH connection, and then it accesses our end-to-end encrypted files but in doing so, it automatically detects our Cryptomator Vault (because it’s built into Mountain Duck) And it then allows us (if we want) to UNLOCK our Cryptomator Vault and access it:
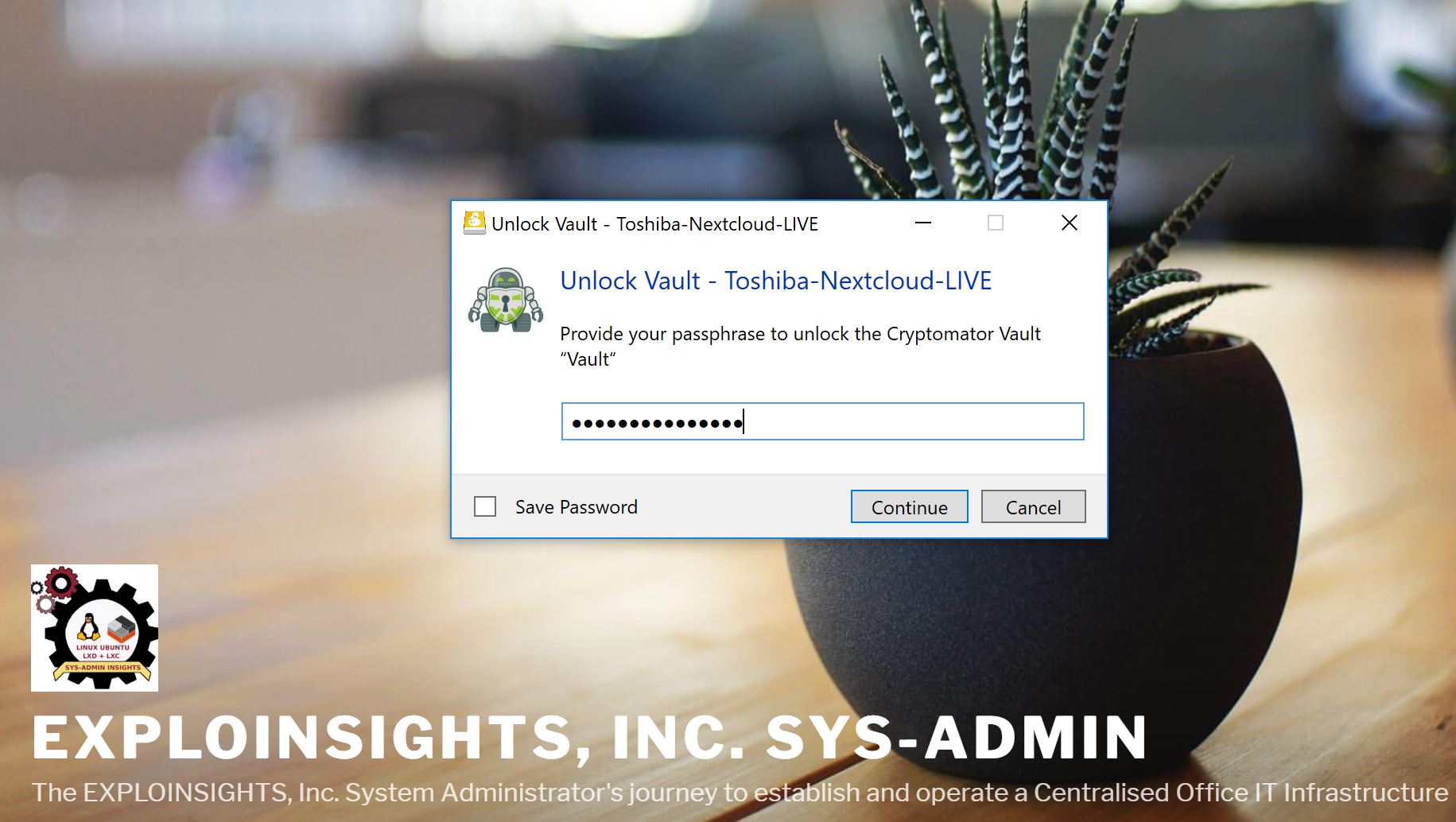
So in one operation and three “codes”, we can securely connect to our Nextcloud client container via secure SSH and access our end-to-end encrypted files from anywhere in the world (where there’s internet!).
And Mountain Duck makes this easier because it allows you to bookmark the connection: open Mountain Duck and click a bookmark to the SSH server then enter your SSH password/2FA code. Mountain Duck logs into your server and accesses the files located there. It can even remember your passwords if you want (we don’t do that, as we don’t trust Windows much at all), but you could configure this to JUST require a 2FA code if you want.
The whole process takes, maybe, 30 seconds including the time to get the phone out and obtain a 2FA code. Not bad! And once you have done that, you can work on your END TO END encrypted files stored on your office based Nextcloud client container files from anywhere in the world. No files are needed to be on your PC – in the office or on the road. Everything remains solidly encrypted so if you do get hacked, there are no readable data that can be stolen, so at least that threat is low. And everything is going through modern, secure OpenSSH transfer protocols, which in our case, makes us sleep a lot better than having some proprietary code with back-doors and all sorts of unpleasant surprises that always seem to arise.
The catch? Well, you do need internet connectivity or you can do NOTHING on your data. The risk in the office is low, but when your on the road it does happen, so it’s still not perfect. 🙂
Also, you do have to set this stuff up with some poor SysAdmin. But if we can do it, probably anyone can?
Finally, this is what it looks like for real after we go through that hard-to-explain-but-easy-to-do login. A window appears and you can see your files just like a normal file view on your Windows PC.
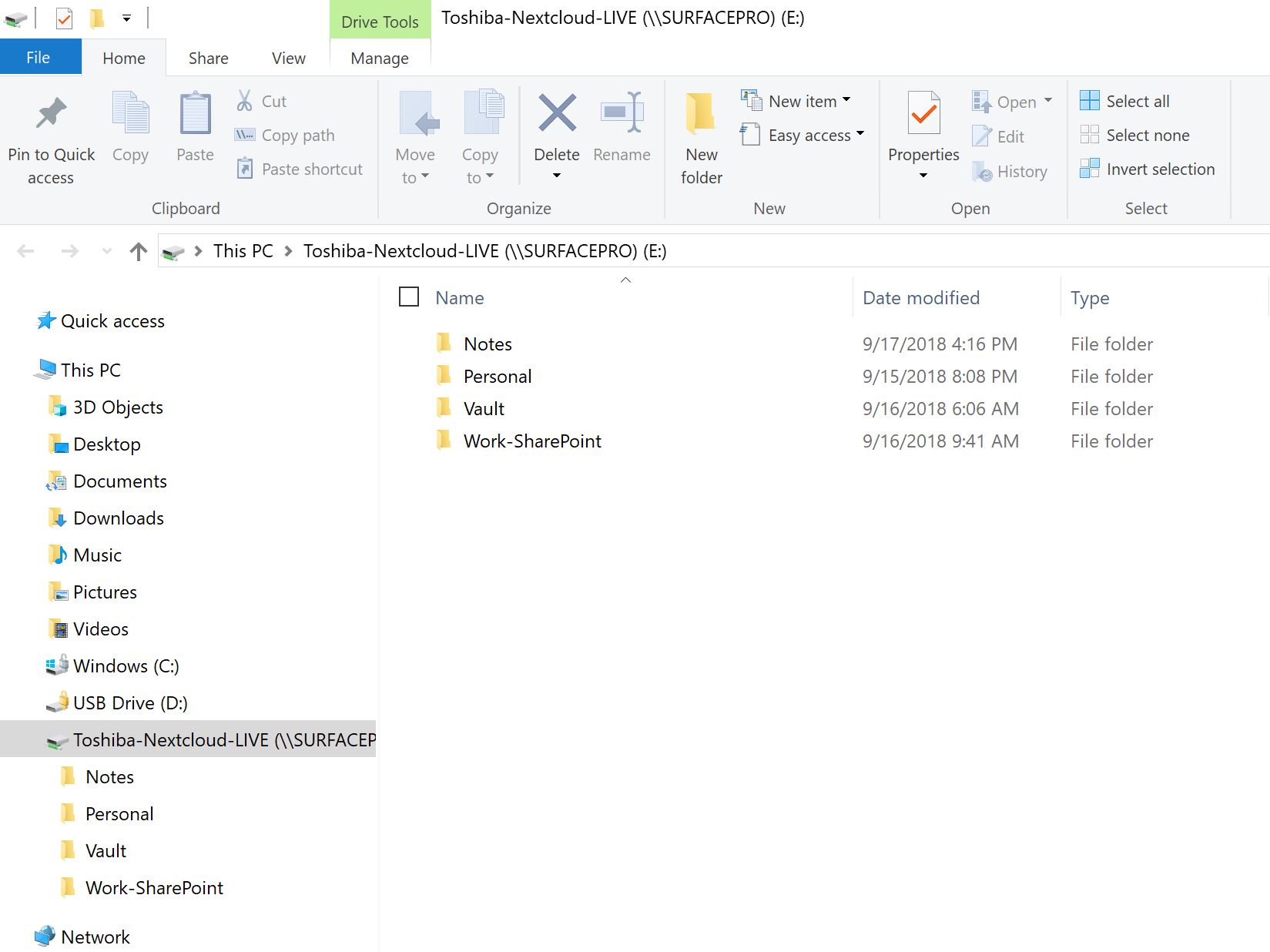
Above is a regular Windows Explorer window, accessing the Nextcloud client container files via fast and secure SSH. The folder ‘Vault’ is actually a Cryptomator end-to-end encrypted folder, but because we have entered the credentials (above), it can be accessed like any other. Files inside can be copied, edited, saved, shared, printed etc. just as files in the other folders. It’s totally transparent, and it’s TOTALLY AWESOME. The files in the Nextcloud client container (and the Nextcloud server) remain fully encrypted all the time. A file ONLY gets decrypted when it’s selected and downloaded by the user. Viewing a file in explorer (as in the view above) does NOT decrypt it – you have to double-click etc. the file to initiate downloading and decryption. All your changes get immediately sync’d to the Nextcloud client container (which immediately sync’s everything back to the server). Nothing gets stored on the PC you are using to work on your files unless you deliberately save it to the device.
So, THIS is how WE roll our own end-to-end encrypted data storage. How do you do yours?
questions or comments by email only [email protected]









 In our quest to migrate away from the relentlessly privacy-mining Microsoft products, we have discovered
In our quest to migrate away from the relentlessly privacy-mining Microsoft products, we have discovered