

So if anyone is enjoying the ride bought on by NIST-800-171, you’ll know that data encryption is one of the many rages. And a lovely thing it is too – AES encryption is safe from ANYONE this side of Quantum computers. What’s not to love here?
Windows has Bitlocker. Easy to use, albeit proprietary. EXPLOINSIGHTS, Inc. uses it for mobile Windows devices as one of three major data encryption regimes employed as part of the NIST compliance for the company (translated into English: We don’t trust BitLocker alone :-)).
So, how hard can it be to enable full disk encryption on a Linux server? Answer: dead easy – it’s part of the installer process for Ubuntu, for example.
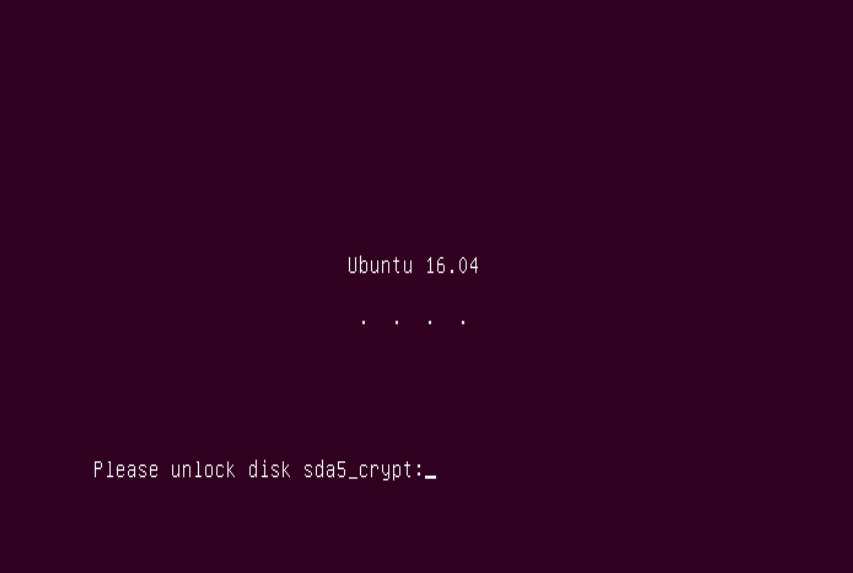
The more INTERESTING question, and the subject of this article: how EASY is it to remotely and securely decrypt a Linux server that employs full disk encryption? Answer: it’s a nightmare. Trust us, we know. 🙁
BUT it can be done. And this record here is to point people in the right direction for doing just that. Firstly, google is your friend, so whatever your distro, ask Google. I use Ubuntu Linux, so I found several useful online articles. The rest of this article is Ubuntu based:
Perform your server (or Desktop) Linux install using full disk encryption. This HAS to be done locally, as does the next steps:
This post: https://www.theo-andreou.org/?p=1579 is genius. Except where it isn’t, if you see what we mean.
- The article will work for you until you get to the line:
echo IP=10.0.0.67::10.0.0.1:255.255.255.0:encrypted-system:eth0:off >> /etc/initramfs-tools/initramfs.confHe doesn’t explain the above line well. Here’s our attempt:
echo IP=HOSTIPADDRESS::HOSTDHCPSERVER:255.255.255.0:HOSTNAME:<SEE-BELOW>:off
- Hopefully our version clarifies things. When you create your server, it has a name. It could be, e.g. “MyServer”. Whatever it is, it goes in place of “HOSTNAME” above. This is not terribly important; but this next bit is:
- The <SEE-BELOW>:off really means you have to insert the name of your network adapter. In days of old, it was called ‘eth0’, but rarely now. So if you use the ‘eth0’ expression, as stated in the article, the darn thing WON’T WORK. We know. We tried. We failed. It took us ages to figure that out.
- To find your network adapter name, use this command:
ls /sys/class/net
…and it will show you the names of your network adaptors. Ours is enp3s0, so We have to enter:
HOSTIP::HOSTDHCP:255.255.255.0:enp3s0:off
…at the end of the /etc/initramfs-tools/initramfs.conf file. Your adaptor name will likely be different.
- Example, for a regular small-business router, that has 192.168.1.1 as the router address and also the place where dhcp requests go):
echo IP=192.168.1.115::192.168.1.1:255.255.255.0:mypcservername:enp3s0:off
- If you are trying a remote LUKS unlock then…GOOD LUCK! It’s hard. It’s also totally satisfying to watch a linux-OS hard disk encryption screen disappear after a remote login, and is perhaps even worth the effort (PERHAPS!!). It’s not easy… #JustSaying
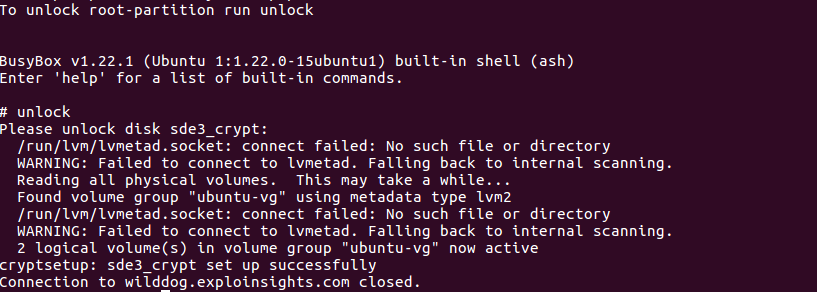
- Here’s a screen-grab of me successfully unlocking one of our servers remotely. We use public-key SSH login, and then busybox gives us a small menu of commands. The one we want is ‘unlock’. After entry, you are prompted for the decryption password. If the key is accepted, the drive unlocks and you see ‘cryptsetup: <drive-ref> set up successfully:

 simply no excuse for running an insecure site these days, as high quality HTTPS: certificates from a CA are free of charge (but not free of effort) – e.g “
simply no excuse for running an insecure site these days, as high quality HTTPS: certificates from a CA are free of charge (but not free of effort) – e.g “